「読んde!!ココVer.11」活用のススメ〜データ再利用にはPDFテキスト化がベスト〜(2/3 ページ)
ところで、紙に印刷された文書をScanSnapで読み取ってPDF化するという使い方は、ペーパーレスを実現する上で非常に有効である。しかし、ScanSnapでPDF化したデータを再利用する場合、1枚の画像としてPDF化(ここでは便宜上PDF画像と呼ぶ)されているため、PDFビューアの選択ツールではテキストを選択することはできない。

しかし、読んde!!ココがインストールされていれば話は違ってくる。ScanSnapに付属の「Acrobat 7.0 Standard日本語版」を起動してScanSnapでPDF化したデータを開き、画像(PDF画像)を選択すると右クリックメニューに「OCRを使用してテキストとして認識」という項目が表示される。これを選択すると、読んde!!ココのエンジンによりOCR処理が実行され、PDF画像からテキストを抽出できる。抽出されたテキストは、標準では「透明テキスト」としてPDFに埋め込まれるのだが、そのまま利用できる精度とは言い難い。
 読んde!!ココの認識エンジンを利用して、PDF画像からテキストを抽出できる
読んde!!ココの認識エンジンを利用して、PDF画像からテキストを抽出できる

データの再利用にはPDFテキスト化がおすすめ
つまり、ScanSnapで直接PDF化したデータは、紙の文書の電子保存/閲覧用と考えた方がよい。データの再利用を考えているのであれば、手間を惜しまずに読んde!!ココを利用してPDF化した方がよいだろう。読んde!!ココでOCR処理をかけ、誤認識を修正してからPDF化したデータは、そのままテキストを選択して再利用することが可能だからだ(便宜上、これをPDFテキストと呼ぶ)。


また、ScanSnapでPDF画像化してからOCR処理をかけるのと、読んde!!ココでOCR処理してからPDFテキスト化するのとでは、手順が異なってくる点にも注目したい。
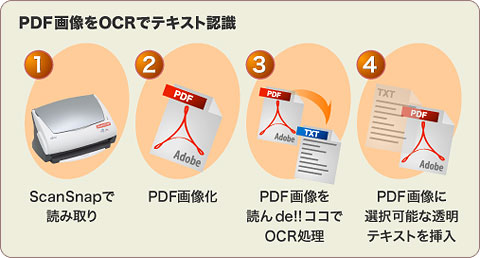

このように、手順も1つ減っている。もちろん、元データのレイアウト等は変わってしまうため、PDF画像化しておくことも重要あろう。しかし、印刷された文書をPDF画像化して保存するのは当然として、時間のあるときに読んde!!ココでPDFテキスト化しておけば、いざというときに役に立つはずだ。
OCRソフトの認識精度を鍛えろ!
Copyright © ITmedia, Inc. All Rights Reserved.
アクセストップ10
- AIに予算20万円以下でピラーレスケースのビジネスPCを組んでもらって分かったこと (2024年05月04日)
- WindowsデバイスでVPN接続ができない不具合/NVIDIAのローカルAI「ChatRTX」にAIモデルを追加 (2024年05月05日)
- サンワ、ペンを持つように操作できるペン型マウス (2024年05月01日)
- あなたのPCのWindows 10/11の「ライセンス」はどうなっている? 調べる方法をチェック! (2023年10月20日)
- Core i9搭載のミニPC「Minisforum NAB9」は最大4画面出力に対応 ワンタッチでカバーも取れる その実力をチェックした (2024年05月01日)
- レノボ「Legion Go」の“強さ”はどれだけ変わる? 電源モードごとにパフォーマンスをチェック!【レビュー後編】 (2024年05月03日)
- Intel N100搭載のChromebookは本当に重たくない? Lenovo IdeaPad Flex 3i Gen 8で動作をチェック! (2024年05月02日)
- 「Windows 11 Home」をおトクに「Windows 11 Pro」へアップグレードする方法 (2022年04月15日)
- Steamで「農業フェス」開催中! ポイントショップでは無料アイテムも (2024年05月03日)
- 万が一の備えに! Windows PCのリカバリーメディアを用意する方法【Windows 10/11編】 (2023年08月12日)
過去記事カレンダー
Feed Back
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。